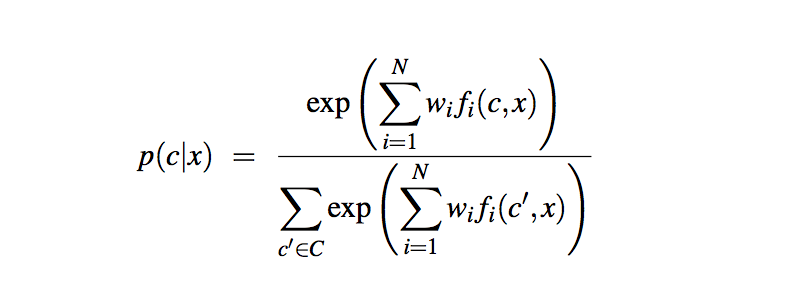Amit Kumar
MS in Computer Science (Data Science) Resume
Resume
Logistic Regression
Logistic regression is a simple classification algorithm. For example, it can be used to classify tweets with positive sentiments from the those with negative sentiments.

Unlike normal regression problem, logistic regression does not output a discrete number to represent the class, instead the output of logistic regression is a valid probability that a given input belongs to a certain class.
Some of the cases where logistic regression can be applied are:
- Email spam filtering
- Text sentiment analysis
- Predict mortality in injured patients
- Predict the risk of developing a given disease
- Predict whether an American voter will vote Democratic or Republican, based on age, income, sex, race, state of residence, votes in previous elections
- And several more applications...
Logistic regression normally refers as classifying the input into one of the two target classes.
In this blog we will discuss the Multinomial Logistic Regression (further in the blog we will refer using MLR). This is used when there are more than two output classes.
Suppose we are doing text classification of sentiments of tweets into three categories namely positive, negative and neutral.
classes = { positive, negative, neutral }
The MLR estimates the proability of an output class conditioned on the the input document by extracting some textual features from the text document and combining them linearly and then appying a function to this combination.
These features are combined property of the input text document as well as the class of the document.
So we can write a feature function as :
fi (x, c)
where
x is the input document given for classification and c is the class of the input document.
To estimate the probability of a certain class c given a document x, we use the following formula.