Amit Kumar
MS in Computer Science (Data Science) Resume
Resume
Running Hadoop In Docker On Mac
In this blog, I will be demonstating how to setup single node Hadoop cluster using Docker on Mac os X. Before actually installing any of these components, let us first understand what these components are and what are they used for.
Apache Hadoop is software framework which is used to perform distributed processing of large data sets accross clusters of computers using simple programming models. Hadoop does a lot more than what is described in this blog. For the sake of simplicity we will only consider the two major components of Hadoop i.e.
- Hadoop File System(HDFS)
- Mappers and Reducers
HDFS is Java based file system that provides reliable, scalable and a distributed way of storing application data into different nodes. In the hadoop cluster, the actual data is stored on the data nodes and the metadata (data about data) is stored on the Name node.

Mapping is the first phase in Hadoop processing in which the entire data is split in tuples of keys and values. After this operation these key value tuples are passed to the shuffler which collects the same type keys from all the mappers and send them to the reducers which finally combine them and writes the output in a file.
Now, lets talk a little bit about Docker. Docker is a tool to provision containers to run different applications without requiring the installation of entire OS. It can be thought of like a Virtual Machine running tool(like VMWare, Virtual box), but it is more flexible, fast, powerful and less resource consuming. You can literally spawn up a container for your application in a fraction of seconds.
Now that we have a basic idea about what Hadoop and Docker is, we will start installing them on our machine.
First we will download the docker dmg file. To download the docker dmg file, go to Docker Store and click on the Get Docker download button.
This will start the download of the dmg file. Once the file is downloaded on your machine, double click the dmg file and then install docker by dragging the docker icon into the acpplication folder.
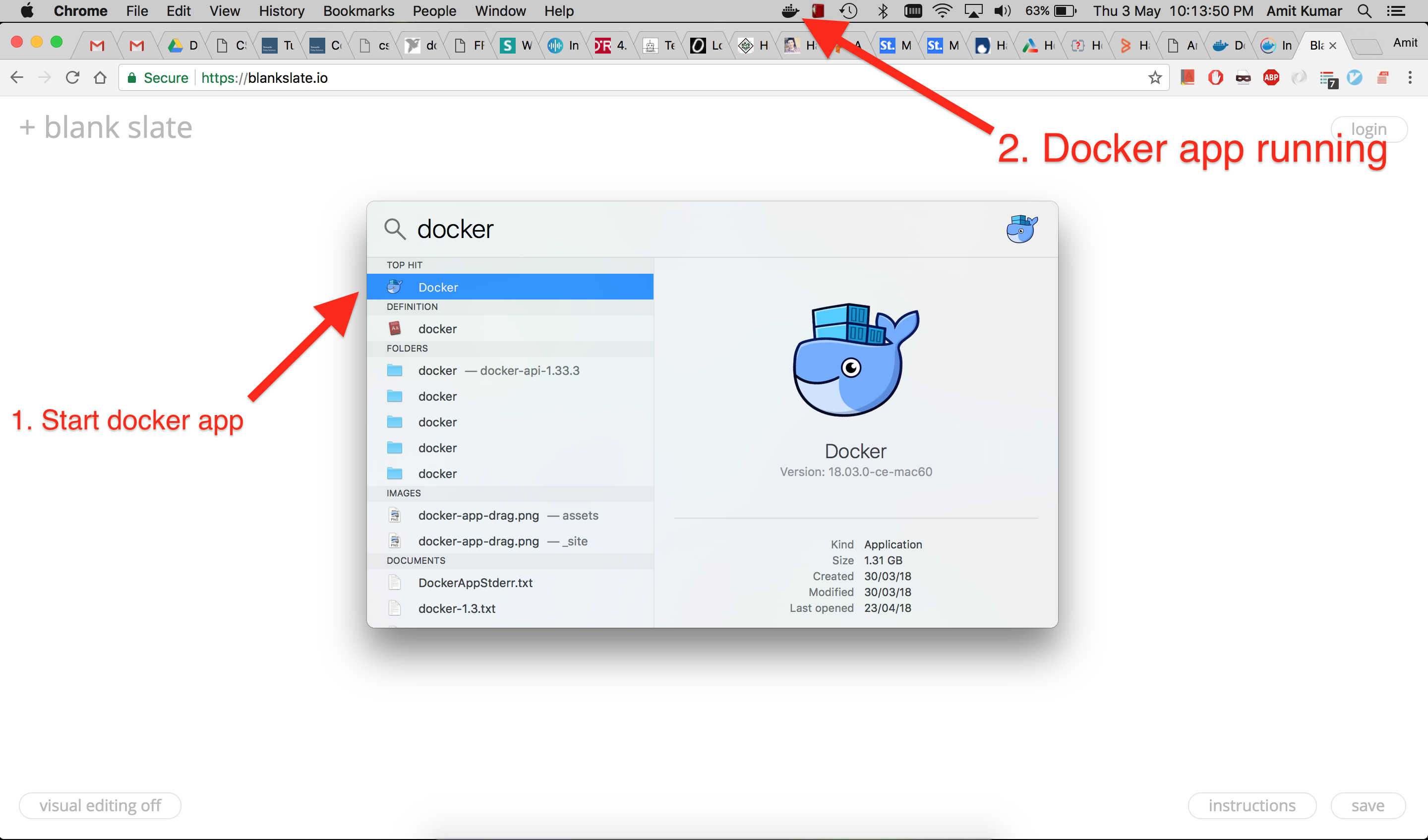
After installing docker, start the docker application from spotlight as shown in the below given picture.
Now to run a test application in your docker, open a terminal a fire the below given query.
docker run hello-world
This command will try to fetch an image named hello-world and run in a container. After running this command you should see output somewhat like this.
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
9bb5a5d4561a: Pull complete
Digest: sha256:f5233545e43561214ca4891fd1157e1c3c563316ed8e237750d59bde73361e77
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.
To generate this message, Docker took the following steps:
1. The Docker client contacted the Docker daemon.
2. The Docker daemon pulled the "hello-world" image from the Docker Hub.
(amd64)
3. The Docker daemon created a new container from that image which runs the
executable that produces the output you are currently reading.
4. The Docker daemon streamed that output to the Docker client, which sent it
to your terminal.
To try something more ambitious, you can run an Ubuntu container with:
$ docker run -it ubuntu bash
Share images, automate workflows, and more with a free Docker ID:
https://hub.docker.com/
For more examples and ideas, visit:
https://docs.docker.com/engine/userguide/
Congratulations, you have successfully installed docker on your machine. Now you can fetch images from docker store or can create your own images using Dockerfile. I will write
a seperate blog on how to write a Dockerfile and Docker compose file.
As we have completed the Docker installation part, now we have to pull the Hadoop image from the docker store and run that in a container. The command we used above not only pulls the image, but it also runs that image in a container after pulling it from docker store. We can separate these two operations by instructing docker only to pull the image and not running it untill asked explicitly. To run the hadoop image just fire the below given command.
docker pull sequenceiq/hadoop-docker:2.7.1
The above command should produce output like this
2.7.1: Pulling from sequenceiq/hadoop-docker
b253335dcf03: Pulling fs layer
a3ed95caeb02: Pulling fs layer
69623ef05416: Pulling fs layer
8d2023764774: Pull complete
ff0696749bf6: Pull complete
.
.
.many such lines in between
.
.
d4ab0c19cb91: Pull complete
824658b0b14c: Pull complete
e5c31d8cbbce: Pull complete
Digest: sha256:2da37e4eeea57bc99dd64987391ce9e1384c63b4fa56b7525a60849a758fb950
Status: Downloaded newer image for sequenceiq/hadoop-docker:2.7.1
To check whether the image downloaded successfully, run the command to list all the images. You should see sequenceiq/hadoop-docker:2.7.1 image among all the listed
docker images.
docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
db_hw_5_submitted_image latest b1f612439afd 7 days ago 3.53GB
ubuntu latest c9d990395902 3 weeks ago 113MB
hello-world latest e38bc07ac18e 3 weeks ago 1.85kB
portainer/portainer latest f6dd93561a5f 4 weeks ago 35MB
sequenceiq/hadoop-docker 2.7.1 42efa33d1fa3 2 years ago 1.76GB
Now that we have got our hadoop image downloaded on our system we need to run it in a container so that we can run the basic map-reduce tasks on it. To run a docker image you need to fire the following command on the terminal.
docker run -it -p 50070:50070 sequenceiq/hadoop-docker:2.7.1 /etc/bootstrap.sh -bash
You must be very puzzeled after seeing such a lengthy command with so many parameters, but don’t worry I will help you in understating what all these parameters actually mean and what this command is doing.
- The
docker runpart instructs the docker program to run an image in a container. This is the basic command to run any container. -itspecifies that that we need to run an interactive process (bashin this case) and docker shouldttysession to the container so that we can execute commands inside the container.-p 50070:50070is used to map the host port with the container port. If you want to access some ports of the container then you need need to specify the mapping with-pflag andhost_machine_port:container_portmapping.sequenceiq/hadoop-docker:2.7.1is the name of the image that we want to run./etc/bootstrap.shis the program we want to start once out docker is up and running.-bashis the argument to the program/etc/bootstrap.sh
After running the above command you should get the bash prompt (as shown below) of the container. Now you can actually execute commands inside this container using this bash prompt.
/
Starting sshd: [ OK ]
18/05/04 01:44:46 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Starting namenodes on [97985498d063]
97985498d063: starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-97985498d063.out
localhost: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-97985498d063.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-root-secondarynamenode-97985498d063.out
18/05/04 01:45:03 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/logs/yarn--resourcemanager-97985498d063.out
localhost: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-97985498d063.out
bash-4.1#
To make sure that the hadoop service is running on you docker container, open any browser on your mac and visit http://localhost:50070/. You should see a page similar to the one give below. This page lists information about the Namenode and HDFS.

Congratulations once again, you have a running Hadoop instance on a docker container. Now you can run the basic in-built hadoop map and reduce programs.
To run these programs run the following commands on the container bash prompt. (Notice the bash-4.1# after you ran the container. This is the container prompt).
bash-4.1# cd $HADOOP_PREFIX bash-4.1# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar grep input output 'dfs[a-z.]+'
Let us split the above command and analyse each of the arguments in to understand their role.
bin/hadoopis used to initiate the hadoop program.- Every map and reduce task is defined in hadoop by giving a jar which contains the implementation of Map and Reduce tasks. In the above command,
jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jaris used to pass the location of the jar file which contains the definition of out map and reduce tasks. grep input output 'dfs[a-z.]+is an argument to our jar file.grepspecify that we want to count the words in all the files present in the directory namedinputput the output in the directory named asoutput
To check the output whether our job ran successfully and gave correct output we need to print the contents of all the files
present in the output directory. Since data in HDFS is spread across multiple data nodes, so we cannot just simply list or open the files by using commands like ls or cat.
Instead we need to tell HDFS that we want to execute these commands to get our output. To do this we need to execute following commands.
bin/hdfs dfs -cat output/*
This should produce output like this.
18/05/04 02:45:42 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
6 dfs.audit.logger
4 dfs.class
3 dfs.server.namenode.
2 dfs.period
2 dfs.audit.log.maxfilesize
2 dfs.audit.log.maxbackupindex
1 dfsmetrics.log
1 dfsadmin
1 dfs.servers
1 dfs.replication
1 dfs.file
The first column in this output represents the count of the number of time the string given in second column occured in all the file present in input direcory.
To have more fun with hadoop you can also try solving the Sudoku. Since by now, you must have got an idea of how can we run map/reduce jobs, it would be pretty easy for you to understand this example.
To solve the sudoku, first create a file named unsolved_sudoku.txt and paste the unsolved sudoku in that file. For example, lets solve this sudoku.
8 5 ? 3 9 ? ? ? ?
? ? 2 ? ? ? ? ? ?
? ? 6 ? 1 ? ? ? 2
? ? 4 ? ? 3 ? 5 9
? ? 8 9 ? 1 4 ? ?
3 2 ? 4 ? ? 8 ? ?
9 ? ? ? 8 ? 5 ? ?
? ? ? ? ? ? 2 ? ?
? ? ? ? 4 5 ? 7 8
Tu solve this sudoku we will be using the same jar file but with different arguments. So the new command will be
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar sudoku unsolved_sudoku.txt
The execution of above command should print the solved sudoku on the terminal.
Solving unsolved_sudoku.txt
8 5 1 3 9 2 6 4 7
4 3 2 6 7 8 1 9 5
7 9 6 5 1 4 3 8 2
6 1 4 8 2 3 7 5 9
5 7 8 9 6 1 4 2 3
3 2 9 4 5 7 8 1 6
9 4 7 2 8 6 5 3 1
1 8 5 7 3 9 2 6 4
2 6 3 1 4 5 9 7 8
Found 1 solutions
Conclusion
We successfully ran a hadoop single node cluster in docker container running on a mac machine. We learned the basics of hadoop operations and how can we run map and reduce jobs using sample hadoop jar files. We solved one sudoku problem as well using the hadoop map/reduce. We also learned that docker containers are the easiest and fastest way to get an application up and running without investing much effort on configuration.